
There exists a chronic confusion as to what the distinction is between your average software engineer (i.e. programmer) and a data scientist. This is totally understandable, considering the fact that both jobs do involve programming and the term “data science” seems so much like the term “computer science”. However, the two differ in some significant ways.
This week we break down the key differences between the two professions to clarify what being a data scientist really means.
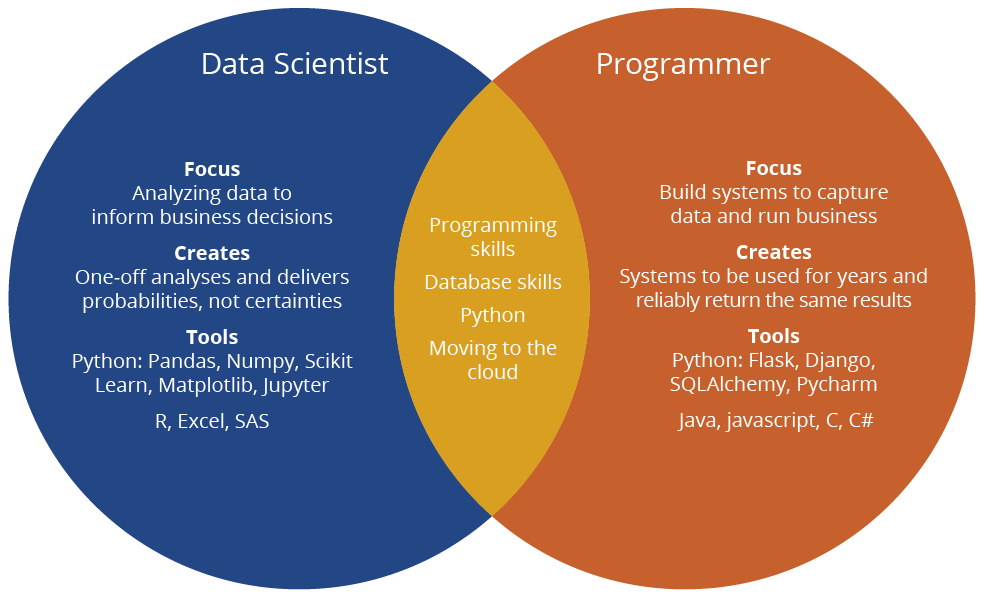
Software engineers “create the products that create the data” – Data scientists analyze the data
Software engineers work on front-end/back-end development, build web and mobile apps, develop operating systems and design software to be used by organizations. Data scientists, on the other hand, focus on building predictive models and developing machine learning capabilities to analyze the data captured by that software.
Data scientists specialize in finding methods for solving business problems that require statistical analysis. They take the data that is created by the organization’s systems and create actionable insights and recommendations for the purposes of optimization in forms like risk mitigation and demand analysis. And while a software engineer will design tools for recurrent use by the business (i.e. they build a system which is then used, relatively unchanged, for years), a data scientist often deals with discrete, situational analyses, which constantly require tailored tools and processes to be created. So, for example, the software engineer might design and build an order entry system that the company uses for 20 years. The data scientist, on the other hand, takes data from that system to determine 1) if there is a correlation between customer geography and sales quantity one month and, in the next month, 2) to determine the effect of customer demographics on purchasing propensity by day of week and time of day.
A software engineer creates deterministic algorithms whereas data scientists create probabilistic algorithms
Every program that a software engineer writes should produce the exact same result every time it runs. For example, the programmer at Amazon.com knows that when you buy four items at five dollars each, the total sale will be $20.
Data scientists, however, because they are dealing with statistics, can’t always guarantee an outcome. Thus, the data scientist can’t tell with certainty that, because you bought a hockey stick you’re also going to buy a bag of pucks. But they can tell the likelihood that you will and, from that, Amazon can decide whether or not to recommend pucks to you when you buy that stick.
While there is some overlap, software engineers and data scientists use different tools.
Nowadays, programmers typically work with SQL databases and programming languages like Java, Javascript, and Python.
Data scientists typically also work with SQL databases as well as Hadoop data stores. They are more likely to work in Excel and frequently program with statistical software like SAS and R. There is also a big trend toward Python but with different libraries (Numpy, Pandas, etc.) than are used by programmers. An interesting programming environment used by data scientists is called Jupyter, which is a tool that allows the data scientist to write a few lines of code, show the intermediate result, add some documentation, and continue on in that mode until a conclusion is reached. This approach helps make the final result, and how it was reached, more obvious to people reviewing and using it.
It is important to remember that although they need them, data scientists are not special because of their coding abilities. Rather, it is their training in mathematics, statistics and social sciences that gives them an edge when it comes to solving business problems with data.
A data scientist will also possess a strong business acumen and a deep intellect. They need a keen sense of observation in order to ask the right questions to guide their analytical process. They have an intellectual passion for getting insights out of data as well as the strategic competence to integrate these insights seamlessly with the overarching business strategy.
Something data scientists and programmers can agree on
All data scientists and most programmers work with multiple data sets. These data sets frequently come from multiple different places, like databases and spreadsheets. The problem is that these data sets usually don\’t include common keys. In other words, for example, there\’s no way to tell whether a person in system A appears in system B or spreadsheet C. To solve this problem, Dataspace now offers a product to find these matches so everyone can tell when related records occur in across these data sets. The product is called Golden Record and more information is available on its website.
Do you need data science, big data, or data warehousing staff?
We at Dataspace have developed some really unique methods for understanding your needs and delivering the contract staff and consultants you need to succeed. Our clients tell us that our track record is unsurpassed. So, if you need help moving your data science efforts forward, let’s talk! Here is our contact info.
I would love to add that programmers typically work with SQL databases and programming languages like Java, Javascript, and Python. Data scientists typically also work with SQL databases as well as Hadoop data stores. They are more likely to work in Excel and frequently program with statistical software like SAS and R 😉